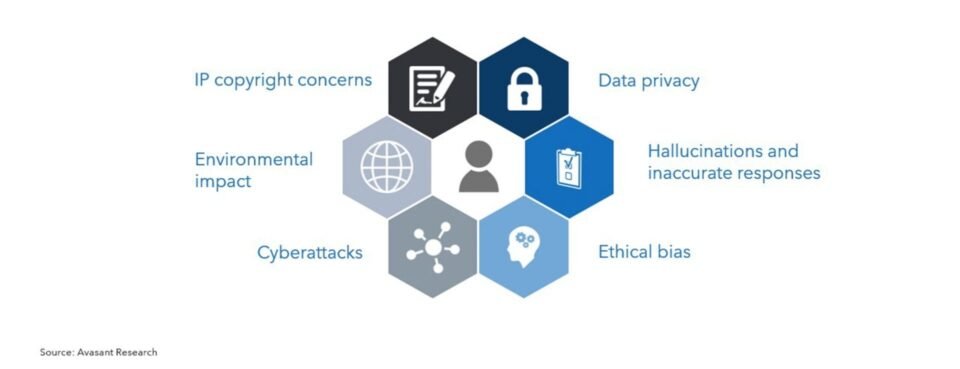
La start-up chinoise en intelligence artificielle DeepSeek a révélé ses processus de filtrage de données pour l’entraînement de ses modèles, soulignant les préoccupations liées aux risques potentiels de “hallucination” et “d’abus”. Basée à Hangzhou, l’entreprise a mis en avant son engagement envers la sécurité de l’IA, en accord avec le renforcement de la supervision de l’industrie par Pékin. Les données utilisées pour le pré-entraînement proviennent d’informations accessibles au public et de données tierces autorisées, sans intention de collecter des données personnelles. DeepSeek utilise des filtres automatisés pour éliminer des contenus tels que les discours de haine et le spam, tout en ayant recours à la détection algorithmique et à la révision humaine pour traiter les biais statistiques dans les grands ensembles de données. Malgré les efforts déployés pour réduire les hallucinations des modèles grâce à des techniques avancées, l’entreprise reconnaît que ce problème reste inévitable. Les utilisateurs sont conseillés de demander l’avis de professionnels lorsque nécessaire, car les modèles génèrent des prédictions plutôt que de fournir des réponses exactes.
Comment DeepSeek gère-t-il les risques de collecte de données et d’hallucination de l’IA ?